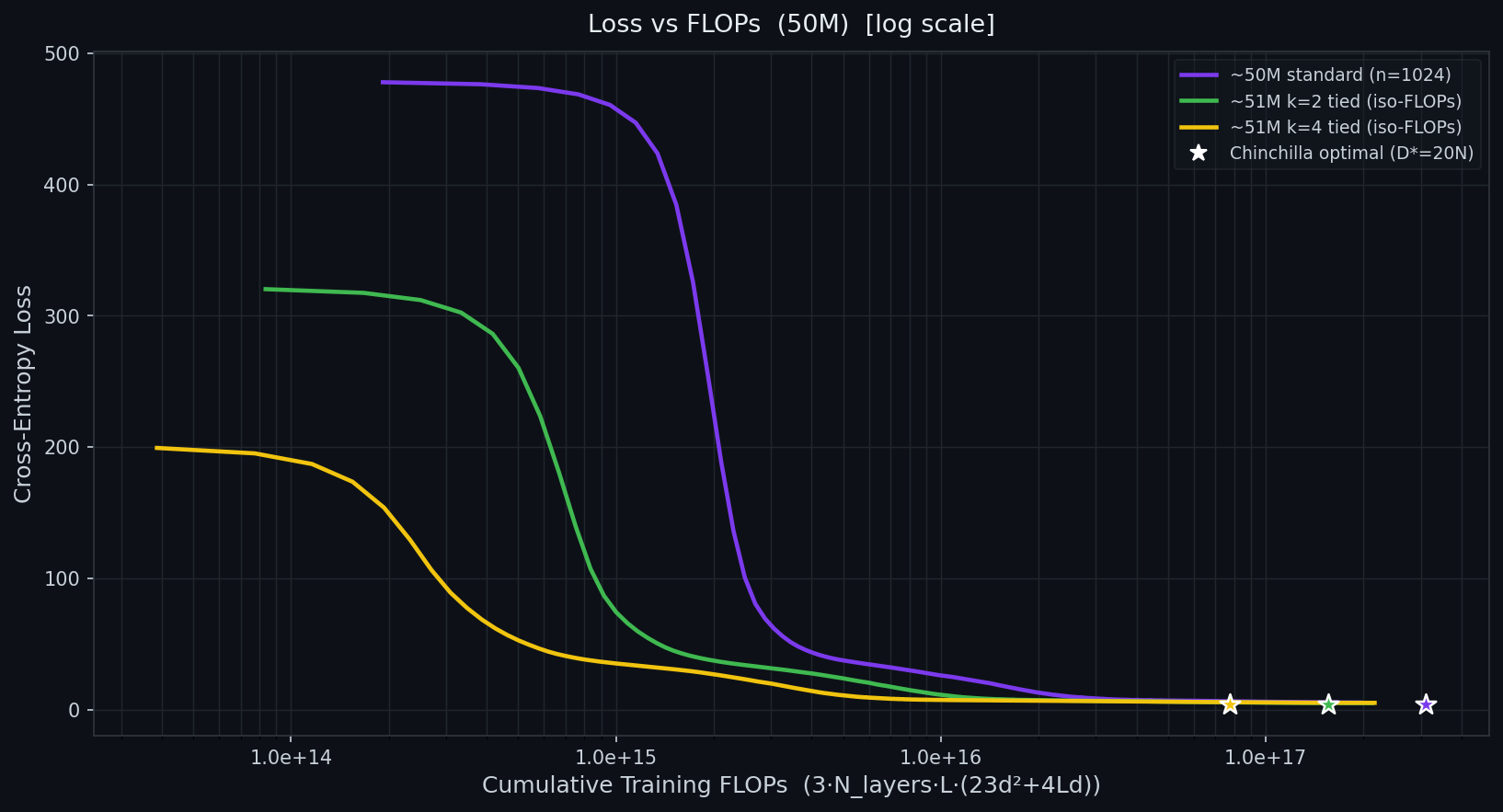
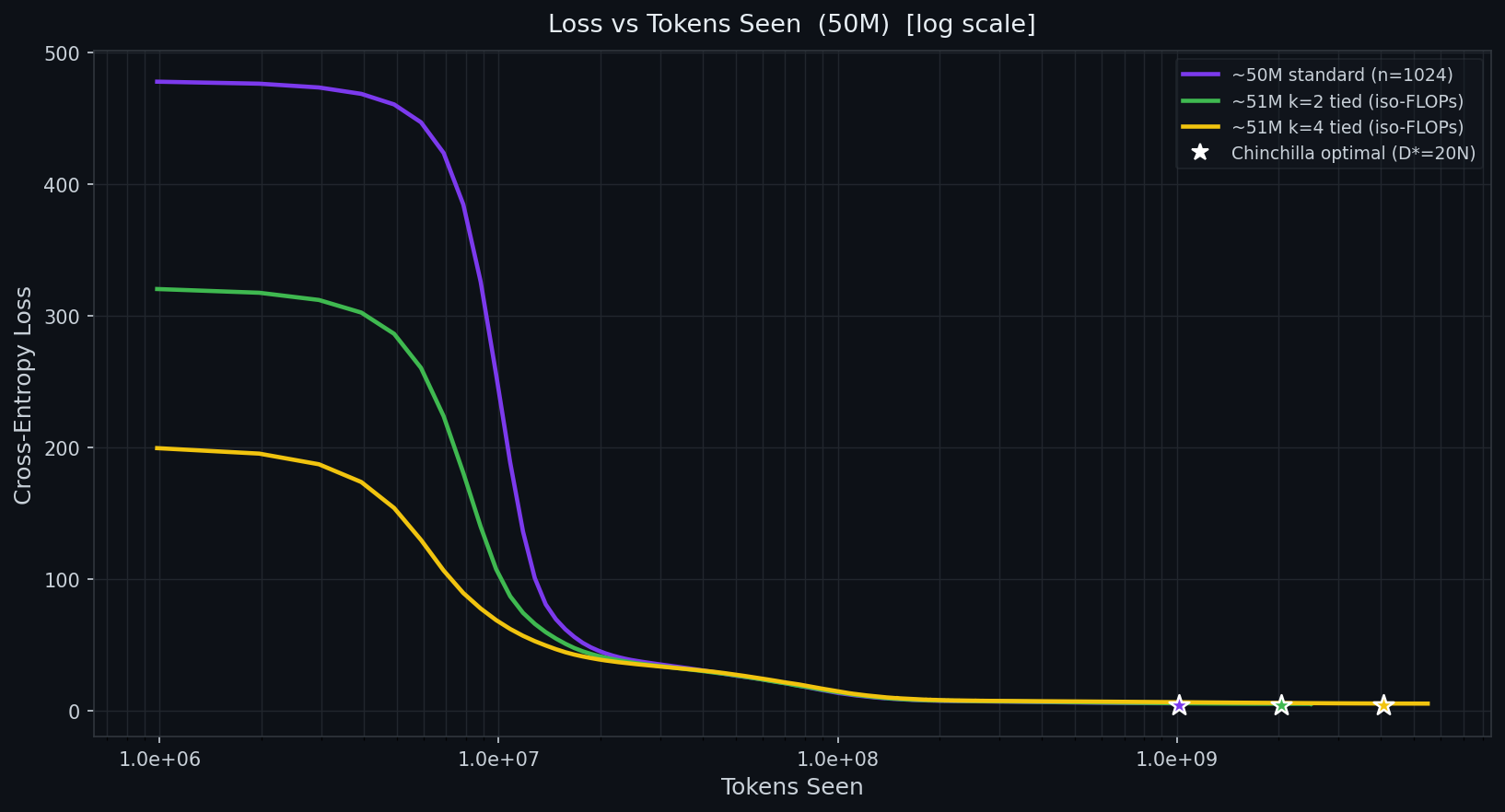
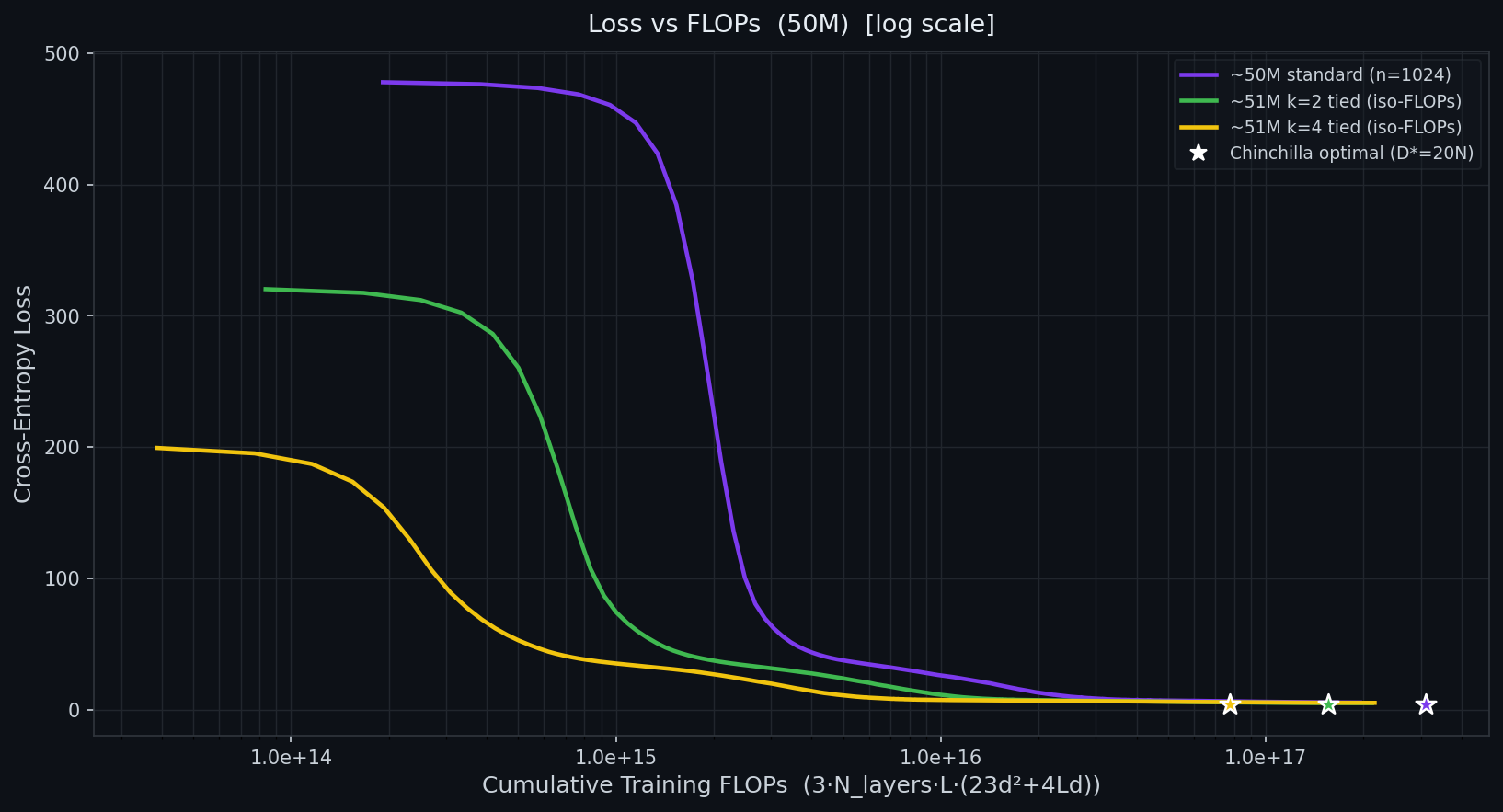
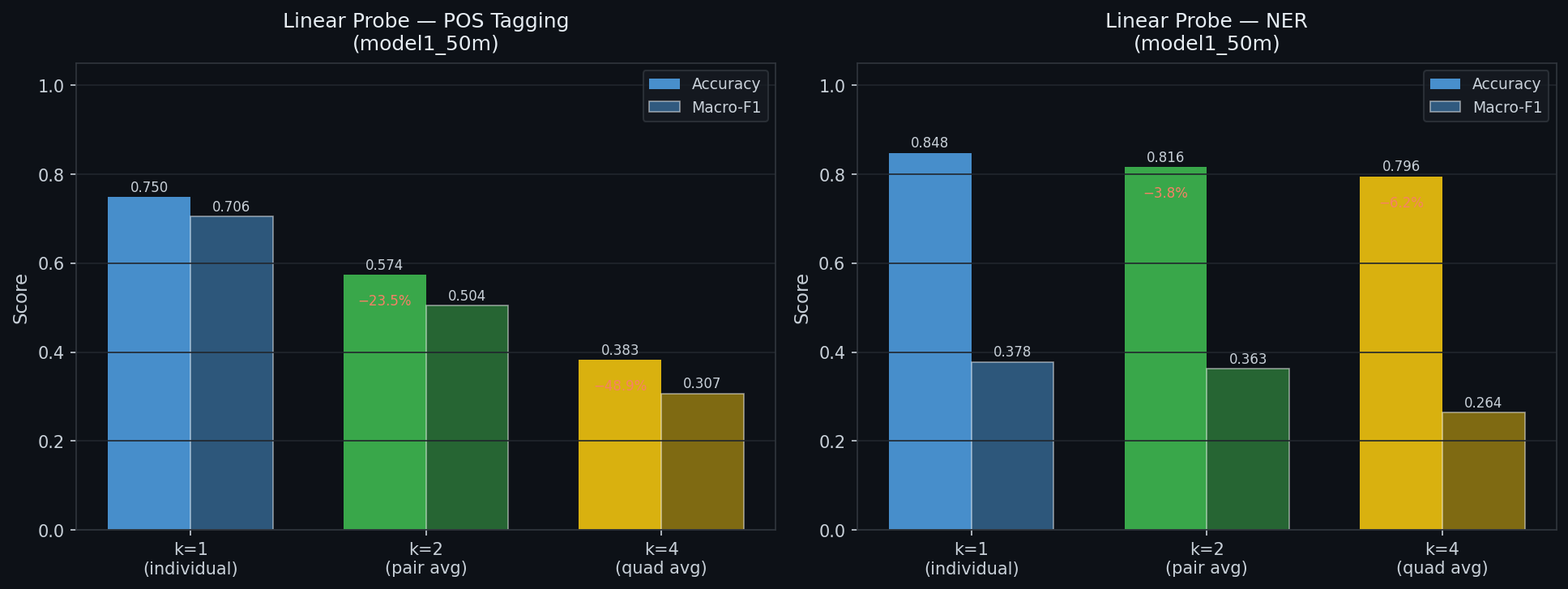
Standard self-attention scales quadratically in context length because every token attends to every other token. At tokens, the attention matrix holds billion entries. At tokens — a plausible requirement for long-horizon agents — it holds trillion. The memory and compute cost is prohibitive even on modern hardware.
Linear attention and sparse attention are partial solutions. Linear attention approximates the softmax kernel, trading exact computation for efficiency but degrading on tasks that require precise token retrieval. Sparse attention restricts the attention pattern to local windows or learned patterns, but must decide ahead of time which tokens are worth attending to — a decision that can only be made correctly with the full context in view.
Memory as the real problem
The core issue is not attention computation — it is the assumption that all past tokens deserve equal representation fidelity. Human working memory does not store every sensory event at full resolution; it stores compressed summaries and retains high-fidelity traces only for events that were subsequently reinforced or retrieved.
A model that mimics this would maintain most historical context in a compressed state, with the option to reconstruct high-fidelity fragments on demand. The quadratic blowup disappears because the dense attention matrix is replaced by a much smaller matrix over compressed summaries.